// pattern: // { term } // term: // '*' matches any sequence of non-/ characters // '?' matches any single non-/ character // '[' [ '^' ] { character-range } ']' // character class (must be non-empty) // c matches character c (c != '*', '?', '\\', '[') // '\\' c matches character c
// character-range: // c matches character c (c != '\\', '-', ']') // '\\' c matches character c // lo '-' hi matches character c for lo <= c <= hi
func FieldsFunc(s []byte, f func(rune) bool) [][]byte // 以符合f方法的字符为分隔符切割s成多个子串(不含分隔符)
1 2 3
f := func(r rune)bool { return r == '#'} a := []byte("This is # and @") fmt.Printf("%s, %q\n", a, bytes.FieldsFunc(a, f)) // This is # and @, ["This is " " and @"]
func Index(s, sep []byte) int // 返回sep在s中的起始位置,如果sep不在s中则返回-1
1 2 3 4 5 6 7 8 9
s := []byte("Hello World!") sep := []byte("Hello") fmt.Printf("'%s' of '%s' is %d\n", sep, s, bytes.Index(s, sep)) // 'Hello' of 'Hello World!' is 0 sep = []byte("World") fmt.Printf("'%s' of '%s' is %d\n", sep, s, bytes.Index(s, sep)) // 'World' of 'Hello World!' is 6 sep = []byte("Bob") fmt.Printf("'%s' of '%s' is %d\n", sep, s, bytes.Index(s, sep)) // 'Bob' of 'Hello World!' is -1 sep = []byte("") fmt.Printf("'%s' of '%s' is %d\n", sep, s, bytes.Index(s, sep)) // '' of 'Hello World!' is 0
func IndexAny(s []byte, chars string) int // 返回chars中任意字符在s中出现的第一个位置,chars为空或找不到则返回-1.
func LastIndexAny(s []byte, chars string) int // 查找s中最后一次出现chars中任意字符的位置,找不到返回-1
func LastIndexByte(s []byte, c byte) int // 查找s中最后一次出现c字节的位置,找不到返回-1
func LastIndexFunc(s []byte, f func(r rune) bool) int // 查找s中符合f方法的字符位置,找不到返回-1
func Map(mapping func(r rune) rune, s []byte) []byte // 将s中的r替换成mapping(r)返回的字符,如果mapping返回负值,则丢弃
1 2 3 4 5 6 7 8 9 10 11
rot13 := func(r rune)rune { switch { case r >= 'A' && r <= 'Z': return'A' + (r-'A'+13)%26 case r >= 'a' && r <= 'z': return'a' + (r-'a'+13)%26 } return r } fmt.Printf("%s\n", bytes.Map(rot13, []byte("'Twas brillig and the slithy gopher..."))) // 'Gjnf oevyyvt naq gur fyvgul tbcure...
func Replace(s, old, new []byte, n int) []byte // 将s中的前n个old替换成new,如果n<0则替换全部
1 2 3 4
s := []byte("Bob takes you to Bob's house.") fmt.Printf("%s\n", bytes.Replace(s, []byte("Bob"), []byte("Lily"), 0)) // Bob takes you to Bob's house. fmt.Printf("%s\n", bytes.Replace(s, []byte("Bob"), []byte("Lily"), 1)) // Lily takes you to Bob's house. fmt.Printf("%s\n", bytes.Replace(s, []byte("Bob"), []byte("Lily"), -1)) // Lily takes you to Lily's house.
// A Buffer is a variable-sized buffer of bytes with Read and Write methods. // The zero value for Buffer is an empty buffer ready to use. type Buffer struct { buf []byte// contents are the bytes buf[off : len(buf)] off int// read at &buf[off], write at &buf[len(buf)] bootstrap [64]byte// memory to hold first slice; helps small buffers avoid allocation. lastRead readOp // last read operation, so that Unread* can work correctly.
// FIXME: it would be advisable to align Buffer to cachelines to avoid false // sharing. }
// bytes.Reader 实现了如下接口: // io.ReadSeeker // io.ReaderAt // io.WriterTo // io.ByteScanner // io.RuneScanner type Reader struct { s []byte i int64// current reading index prevRune int// index of previous rune; or < 0 }
// Reader 实现了对io.Reader对象的缓冲功能 type Reader struct { buf []byte rd io.Reader // reader provided by the client r, w int// buf read and write positions err error lastByte int lastRuneSize int }
Modified time.Time // Go 1.10 ModifiedTime uint16// Deprecated: Legacy MS-DOS date; use Modified instead. ModifiedDate uint16// Deprecated: Legacy MS-DOS time; use Modified instead.
CRC32 uint32 CompressedSize uint32// Deprecated: Use CompressedSize64 instead. UncompressedSize uint32// Deprecated: Use UncompressedSize64 instead. CompressedSize64 uint64// Go 1.1 UncompressedSize64 uint64// Go 1.1 Extra []byte ExternalAttrs uint32// Meaning depends on CreatorVersion }
const ( // Type '0' indicates a regular file.(普通文件) TypeReg = '0' TypeRegA = '\x00'// Deprecated: Use TypeReg instead.
// Type '1' to '6' are header-only flags and may not have a data body. TypeLink = '1'// Hard link(硬链接) TypeSymlink = '2'// Symbolic link(软链接/符号链接) TypeChar = '3'// Character device node(字符设备节点) TypeBlock = '4'// Block device node(块设备节点) TypeDir = '5'// Directory(目录) TypeFifo = '6'// FIFO node
// Type '7' is reserved.(保留项) TypeCont = '7'
// Type 'x' is used by the PAX format to store key-value records that // are only relevant to the next file. // This package transparently handles these types. TypeXHeader = 'x'// 可扩展头部
// Type 'g' is used by the PAX format to store key-value records that // are relevant to all subsequent files. // This package only supports parsing and composing such headers, // but does not currently support persisting the global state across files. TypeXGlobalHeader = 'g'// 全局扩展头部
// Type 'S' indicates a sparse file in the GNU format. TypeGNUSparse = 'S'// 稀疏文件
// Types 'L' and 'K' are used by the GNU format for a meta file // used to store the path or link name for the next file. // This package transparently handles these types. TypeGNULongName = 'L' TypeGNULongLink = 'K' )
变量(主要用于错误输出)
1 2 3 4 5 6
var ( ErrHeader = errors.New("archive/tar: invalid tar header") // 无效的tar头部 ErrWriteTooLong = errors.New("archive/tar: write too long") // 写入数据太长 ErrFieldTooLong = errors.New("archive/tar: header field too long") // 头部太长 ErrWriteAfterClose = errors.New("archive/tar: write after close") // 关闭后写入 )
Devmajor int64// Major device number (valid for TypeChar or TypeBlock)(字符设备或块设备的主设备号) Devminor int64// Minor device number (valid for TypeChar or TypeBlock)(字符设备或块设备的次设备号)
Xattrs map[string]string// Go 1.3 PAXRecords map[string]string// Go 1.10
Format Format // Go 1.10 }
Header的相关方法:
func FileInfoHeader(fi os.FileInfo, link string)(*Header, error) //该方法通过os.FileInfo来创建一个tar.Header,用在对已有文件打包十分方便
type Reader struct { r io.Reader pad int64// Amount of padding (ignored) after current file entry curr fileReader // Reader for current file entry blk block // Buffer to use as temporary local storage
// err is a persistent error. // It is only the responsibility of every exported method of Reader to // ensure that this error is sticky. err error }
type Writer struct { w io.Writer pad int64// Amount of padding to write after current file entry curr fileWriter // Writer for current file entry hdr Header // Shallow copy of Header that is safe for mutations blk block // Buffer to use as temporary local storage
// err is a persistent error. // It is only the responsibility of every exported method of Writer to // ensure that this error is sticky. err error }
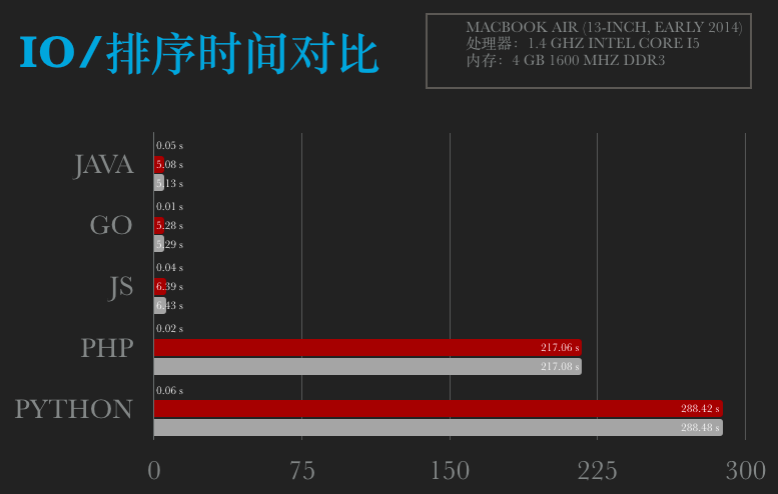
funcmain() { fileName := "Data.txt" data := make([]int, 0, 50000) start := time.Now() fi, err := os.Open(fileName) if err != nil { fmt.Printf("Error: %s\n", err) return } defer fi.Close() br := bufio.NewReader(fi) for { a, _, c := br.ReadLine() if c == io.EOF { break } num, _ := strconv.Atoi(string(a)) data = append(data, num) } endReadTime := time.Now() fmt.Printf("Read time: %fs\n", endReadTime.Sub(start).Seconds()) BubbleSort(data) endTime := time.Now() fmt.Printf("Sort time: %fs\n", endTime.Sub(endReadTime).Seconds()) fmt.Printf("finished time: %fs\n", endTime.Sub(start).Seconds()) }
funcBubbleSort(arr []int) { length := len(arr) var flag int var tmp int for i := 0; i < length; i++ { flag = 0 for j := 1; j < (length - i); j++ { if arr[j] < arr[j-1] { tmp = arr[j] arr[j] = arr[j-1] arr[j-1] = tmp flag = 1 } } if flag == 0 { return } } }
~/Workspaces/go » go run main.go cost time: 0.952737 ------------------------------------------------------- ~/Workspaces/go » go run main.go cost time: 0.983901 ------------------------------------------------------- ~/Workspaces/go » go run main.go cost time: 0.967799 ------------------------------------------------------- ~/Workspaces/go » go run main.go cost time: 0.972302 ------------------------------------------------------- ~/Workspaces/go » go run main.go cost time: 0.980509
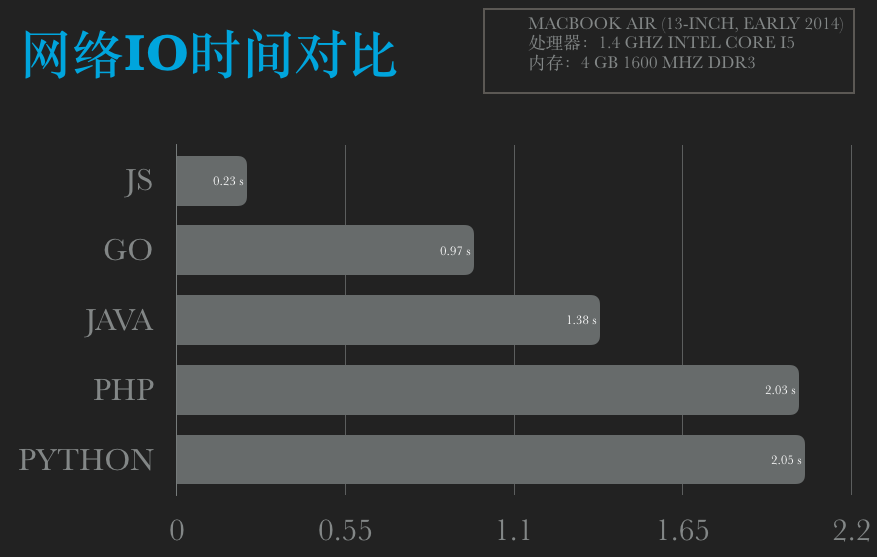
res_data = urllib2.urlopen(req) res = res_data.read() return res t = time.time() for i in xrange(0, 20): # print "Get("+str(i)+"):" data = get("http://2018.ip138.com/ic.asp?count="+str(i)) # print data print'Python time: %.02fs' % (time.time() - t)
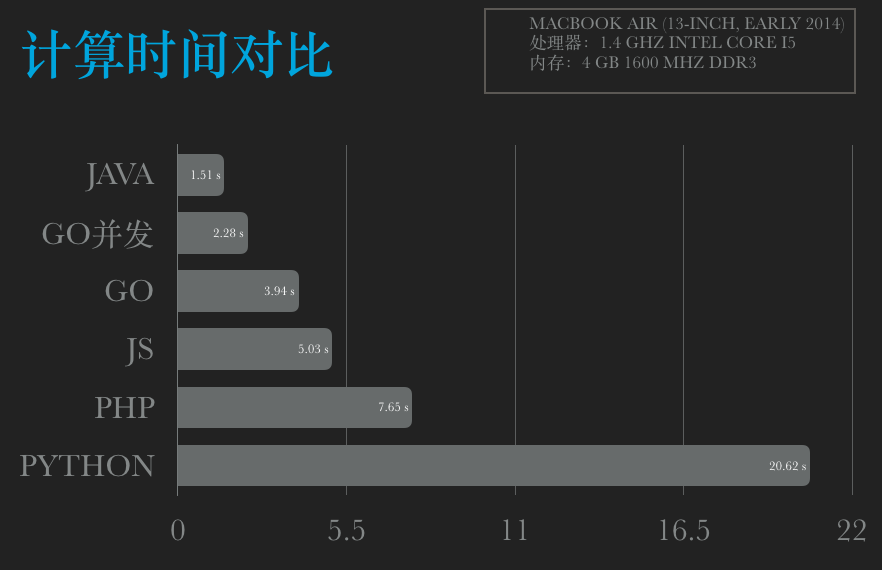
funcmain() { t1 := time.Now() for i := 0; i < 10000000; i++ { Aaa(float64(i)) } t2 := time.Now() fmt.Printf("Go time: %f s\n", t2.Sub(t1).Seconds()) }
funcAaa(i float64) { var a float64 = i + 1 var b float64 = 2.3 s := "abcdefkkbghisdfdfdsfds"
if a > b { a++ } else { b = b + 1 }
if a == b { b = b + 1 }
c := a*b + a/b - math.Pow(a, 2) d := s[0:strings.Index(s, "kkb")] + strconv.FormatFloat(c, 'E', -1, 64) _ = d }
测试结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
~/Workspaces/GoLand/src/Aaa » go build main.go ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 4.083166 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 4.095651 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 4.154200 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 4.175203 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 4.111375 s
~/Workspaces/GoLand/src/Aaa » go build main.go ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 2.326077 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 2.270769 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 2.277345 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 2.252540 s ------------------------------------------------------- ~/Workspaces/GoLand/src/Aaa » ./main Go time: 2.255374 s
var t1 = (newDate()).getTime(); for(var i=0; i<10000000; i++){ aaa(i); } var t2 = (newDate()).getTime(); console.log("nodejs time:" + (t2 - t1) + "ms"); functionaaa(i){ var a = i + 1; var b = 2.3; var s = "abcdefkkbghisdfdfdsfds"; if(a > b){ ++a; }else{ b = b + 1; } if(a == b){ b = b + 1; } var c = a * b + a / b - Math.pow(a, 2); var d = s.substring(0, s.indexOf("kkb")) + c.toString(); }
import sys, time, math defaaa(i): a = i + 1 b = 2.3 s = "abcdefkkbghisdfdfdsfds" if a > b: a = a + 1 else: b = b + 1 if a == b: b = b + 1 c = a * b +a / b - math.pow(a, 2) d = s[0: s.find("kkb")] + str(c) t = time.time() for i in xrange(0, 10000000): aaa(i) print'Python time: %.02f s' % (time.time() - t)