

引用符号'&'在foreach循环中的惊喜
工作中总会遇到一些奇奇怪怪的由前人所写下的不可置疑的代码,如果你仅仅跟着眼前所见的代码去理解他人的思路,Well You have fell into a terrible situation.
贴一段示例代码:
1 |
|
你也许会回答这样一个输出结果:

工作中总会遇到一些奇奇怪怪的由前人所写下的不可置疑的代码,如果你仅仅跟着眼前所见的代码去理解他人的思路,Well You have fell into a terrible situation.
贴一段示例代码:
1 |
|
你也许会回答这样一个输出结果:
渐进符号是分析算法时间复杂度的常用记号,对于某个规模为n的问题,当n足够大时,就可以忽略掉复杂度表达式中的低阶项和最高次项的系数,由此引出“渐进复杂度”,并且用渐进符号来对“渐进复杂度”进行表达。
1、O(大O符号):上界
定义:若存在两个正的常数 c 和 n0 , 对于任意 n≥n0 , 都有 T( n)≤cf( n) ,则称T( n) = O( f( n) )(或称算法在 O( f( n))中)。
大 O 符号用来描述增长率的上限,表示 T( n)的增长最多像 f( n)增长的那样快,也就是说, 当输入规模为 n时, 算法消耗时间的最大值,这个上限的阶越低, 结果就越有价值。上界是对算法效率的一种承诺。
大O符号的含义如下图所示: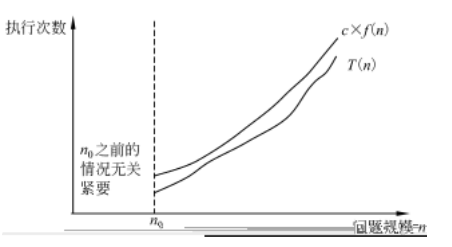
2、Ω(大Ω符号):下界
定义:若存在两个正的常数 c和 n0 ,对于任意 n≥ n0 , 都有 T( n)≥cg( n) ,则称T( n) = Ω( g( n) )(或称算法在 Ω( g( n) )中)。
大 Ω符号用来描述增长率的下限, 也就是说, 当输入规模为 n 时,算法消耗时间的最小值。与大 O 符号对称, 这个下限的阶越高,结果就越有价值。
【选择题】
设文件索引节点中有8个地址项,每个地址项大小为4字节,其中5个地址项为直接地址索引,2个地址项是一级间接地址索引,1个地址项是二级间接地址索引,磁盘索引块和磁盘数据块大小为1KB。若要访问文件的逻辑块号分别为5和518,则系统应分别采用____;而且可表示的单个文件最大长度是____KB。
第一空选项:
第二空选项:
解答:
由题所知,索引快大小1KB,每个地址项4Byte,则每个索引块包含地址项为1KB/4Byte=256个。
直接地址索引实际拥有5*1个块,块号0~4
一级间接地址索引实际拥有2*256个块,块号5260,261516
二级间接地址索引实际拥有1*256*256个块,块号517~66052
逻辑块号为5的在一级间接地址索引,逻辑块号为518的在二级间接地址索引。
如上计算,文件索引节点中可以有66053个索引块,即最大文件长度为66053*1KB
MacOS版本:
1 | brew install certbot |
Ubuntu版本:
1 | sudo apt-get update |
PHP版本从7.2开始不再支持mcrypt扩展,所以我们需要使用OpenSSl对其进行替换。本文仅列出部分算法的替换示例,所以不在本文出现的算法或模式需要自行尝试,顺水推舟。
本文替换案例:
在使用 MCRYPT_RIJNDAEL_128 的地方,如果秘钥长度分别为16、24、32,则加密算法用 AES-128-ECB、AES-192-ECB、AES-256-ECB,BlockSize为16、24、32。
首先列出需要用到的数据填充方法:
1 | function ZeroPadding($str, $block = 16) { |
写这篇笔记的目的
为了应对后续开发生涯中可能遇到的种种情况以及分布式计算的趋势(讲白了就是后续对工作会很有帮助)。如若总是依赖http-api/restful编写并提供外部调用接口,当接口数量不断上升,文档内容不断增加,这给设计者和使用者都带来非常不好的体验,而RPC在这体就现出了非常大的优势。我将自己的理解和体会以及学习的过程记录在这里,以便今后遇到问题能够从这儿获得些许的线索以及提供一个参考给同道中人。
前提
不妨思考这样一个情形:作为接口设计者,我早已经定义好的接口的请求方式(RESTFul)和返回结构(json),但是每个接口我还需要另外维护一个文档来说明各个接口的用法(请求参数)和解释返回的结果(字段描述)。而对于接口的调用者而言,不但要去文档中查找自己需要的接口并阅读说明,在实际调用中,还要以防接口提供者返回非既定结构的结果而导致的报错。
介绍
Remote Procedure Call(远程过程调用),简称RPC。它可以使得调用远程服务接口如同调用本地方法一样简单。虽然实质还是通过网络通信,但是相比http请求api的网络开销还是极小的,其原因简单来说,HTTP协议每次请求都需要建立TCP连接,就会涉及3次握手的网络开销问题以及冗余报文,而rpc直接使用TCP多路复用(gRPC基于HTTP/2)无需重复建立连接。就文档方面而言,编写一份开发文档足矣,因为接口的定义由接口定义语言(IDL)来完成,而阅读IDL便可理解所有接口,并且通过编译器可以将IDL编译成不同的语言实现源码(gRPC通过protoc编译器将protobuf编译)。其他优点例如:注册、监控、发布等的这里不做论述。
Go-Server
GRPC的官方资源:go get google.golang.org/grpc
GRPC的镜像资源:https://github.com/grpc/grpc
官方的相关示列可以在grpc/examples/中找到。
使用protocol buffers去定义gRPC service和方法 request以及 response 的类型。
新增并编辑文件:something.proto
1 | syntax = "proto3"; |
Go-代码
1 | protoc --go_out=plugins=grpc:. something.proto |
运行这个命令后,会在当前目录生成一个something.pb.go文件,内容包含:
PHP-代码
1 | protoc --proto_path=./ --php_out=./ --grpc_out=./ --plugin=protoc-gen-grpc=/Users/anthony/git/grpc/bins/opt/grpc_php_plugin ./something.proto |
其中/Users/anthony/git/grpc/bins/opt/grpc_php_plugin对应从git中获取的<grpc-git-path>/bins/opt/grpc_php_plugin
运行这个命令后,会在当前目录生成如下:
首先我们需要实现服务定义的服务接口:
something/something.go:
1 | package something |
然后运行一个gRPC服务器,注册我们的服务并监听来自客户端的请求:
server.go:
1 | package main |
简单执行命令:go run server.go,然后等待客户端请求。
Go-Client
创建文件client.go:
1 | package main |
PHP-Client
PHP首先要安装grpc的php扩展,下载地址:http://pecl.php.net/package/gRPC
直接使用phpize安装:
1 | tar -zxf grpc-1.17.0.tgz |
执行php -m | grep grpc 应该会输出”grpc”,就代表成功了。
创建客户端文件,这里需要用到composer获取两个包,其中composer.json内容为:
1 | { |
something.php:
1 |
|
Go-Client
我们先编译一下:go build client.go,输出可执行文件client,然后直接运行:
./client Anthony./client ny分别输出如下:
1 | 2018/12/02 13:40:15 Find user: id:1 name:"Anthony" age:24 sex:Female |
1 | 2018/12/02 13:40:25 Find user: |
PHP-Client
直接执行PHP文件:php something.php Anthony和php something.php ny,结果如下:
1 | int(1) |
1 | int(0) |
本次笔记接近结尾了,内容很简单,主要记录使用grpc的大体流程。为后续的测试做一点点的准备。
参考资料
一天一个Golang包,慢慢学习之“path/filepath”
上一篇学习了path包,了解了几个对路径处理的方法。今天继续完成它的子包“filepath”,包中的函数会根据不同平台做不同的处理,如路径分隔符、卷名等。
官方pkg地址:https://golang.org/pkg/path/filepath
包方法
func Base(path string) stringfunc Clean(path string) stringfunc Dir(path string) stringfunc Ext(path string) stringfunc IsAbs(path string) boolfunc Join(elem ...string) stringfunc Match(pattern, name string) (matched bool, err error)func Split(path string) (dir, file string)
// 以上8种方法跟path包同名方法功能类似
func Abs(path string) (string, error)
// 返回相对当前路径的path的绝对路径
1 | fmt.Println(filepath.Abs("")) |
func EvalSymlinks(path string) (string, error)
// 返回Path的实际路径(如果path是个软链接的话)
1 | fmt.Println(filepath.EvalSymlinks("/etc")) // /private/etc <nil> |
func ToSlash(path string) stringfunc FromSlash(path string) string
// 以上两种方法作主要用于Windows平台。
// 将path中的平台相关的路径分隔符(或’/‘)转换为’/‘(或平台相关的路径分隔符)
func Glob(pattern string) (matches []string, err error)
// 列出与指定模式pattern完全匹配的文件或目录,匹配原则同Match一样。
1 | fmt.Println(filepath.Glob("/usr/*")) |
func HasPrefix(p, prefix string) bool
// 该方法已弃用,不再被建议使用。
func Rel(basepath, targpath string) (string, error)
// 返回targpath相对于basepath的路径。
// 要求二者必须同为“相对路径”或“绝对路径”
1 | fmt.Println(filepath.Rel("/usr/local","/usr/local/bin/go")) // bin/go <nil> |
func SplitList(path string) []string
// 将路径序列path分割为多条独立路径。
// path类似Unix/Linux下的环境变量PATH。
1 | fmt.Printf("%q\n", filepath.SplitList("/bin:/sbin:/usr/bin:/usr/sbin : /usr/local/bin")) |
func VolumeName(path string) string
// 返回路径字符中的卷名
// Windows 中的 C:\Windows 会返回”C:”
// Linux 中的 //dev/host/dir 会返回 //dev/host
func Walk(root string, walkFn WalkFunc) error
// 遍历指定目录root(包括子目录),对遍历到的项目用walkFn函数进行处理。
// walkFn返回nil,则walkFn继续遍历,如果返回SkipDir,则Walk函数跳过当前目录,继续遍历下一目录。
// 如果返回其他错误,则Walk函数终止。
// 在Walk遍历过程中,如遇到错误,则会将错误通过err传递给walkFn,同时跳过出错的项目,继续处理后续项目。
1 | // 打印目录及目录下所有文件及大小 |
一天一个Golang包,慢慢学习之“path”
上一篇学习了bytes包,内容还是有点多,花的时间也多了一点。所以今天补充点小内容-path包。当然,path还有子包:filepath,这个下次再继续。
官方pkg地址:https://golang.org/pkg/path/
包方法
func Base(path string) string
// 返回最后一个元素(目录或文件)的路径
1 | fmt.Println(path.Base("/a/b/")) // b |
func Clean(path string) string
// 返回最洁净的路径,在path比较复杂的情况下使用,可以简化path。
1 | paths := []string{ |
func Dir(path string) string
// 返回元素(目录或文件)的目录路径
1 | fmt.Println(path.Dir("/a/b/c")) // /a/b |
func Ext(path string) string
// 返回path下文件名的后缀
1 | fmt.Println(path.Ext("/a/b/c/bar.css")) // .css |
func IsAbs(path string) bool
// 判断path是否是绝对路径
1 | fmt.Println(path.IsAbs("/dev/null")) // true |
func Join(elem ...string) string
// 将多个路径元素连接成一个,空元素会被忽略。
1 | fmt.Println(path.Join("a", "b", "c")) // a/b/c |
func Match(pattern, name string) (matched bool, err error)
// 判断name是否符合pattern规则,并返回err
1 | // pattern: |
func Split(path string) (dir, file string)
// 返回path的目录和文件名
1 | fmt.Println(path.Split("static/myfile.css")) // static/ myfile.css |
下一篇来学习:path/filepath
一天一个Golang包,慢慢学习之“bytes”
今天学习bytes包,其实之前就已经使用了bytes包的很多方法了,这次主要就是再次熟悉和认识这个包里面的方法。
官方pkg地址:https://golang.org/pkg/bytes/
包方法
func Compare(a, b []byte) int
// 比较a和b两个字节数组。
// if a==b return 0;
// if a < b return -1;
// if a > b return 1;
1 | var a, b []byte |
func Contains(b, subslice []byte) bool
// 检查subslice是不是包含在b中
1 | a := []byte{65, 66, 67, 68, 69, 70} |
func ContainsAny(b []byte, chars string) bool
// 检查b中是否包含chars中的任意字符
1 | a := []byte{65, 66, 67, 68} |
func ContainsRune(b []byte, r rune) bool
// 判断b中是否包含r字符
1 | a := []byte{65, 66, 67 ,68} |
func Count(s, sep []byte) int
// sep在s中的重复次数(sep不重叠),即s=ababab,sep=abab则返回1
1 | a := []byte("ababab") |
func Equal(a, b []byte) bool
// 判断a和b是否相等,nil等同于[]byte()
1 | a := []byte("ABC") |
func EqualFold(s, t []byte) bool
// 判断s和t是否相似,忽略大小写和标题三种格式
1 | a := []byte("abc") |
func Fields(s []byte) [][]byte
// 以连续空白为分隔符切割s成多个子串(不含分隔符)
1 | a := []byte("abc def ABC CBA") |
func FieldsFunc(s []byte, f func(rune) bool) [][]byte
// 以符合f方法的字符为分隔符切割s成多个子串(不含分隔符)
1 | f := func(r rune) bool { return r == '#'} |
func HasPrefix(s, prefix []byte) bool
// 检测s字节切片是否以prefix开头
1 | s := []byte("Hello World!") |
func HasSuffix(s, suffix []byte) bool
// 检测s字节切片是否以suffix结尾
1 | s := []byte("Hello World!") |
func Index(s, sep []byte) int
// 返回sep在s中的起始位置,如果sep不在s中则返回-1
1 | s := []byte("Hello World!") |
func IndexAny(s []byte, chars string) int
// 返回chars中任意字符在s中出现的第一个位置,chars为空或找不到则返回-1.
1 | s := []byte("Hello World!") |
func IndexByte(b []byte, c byte) int
// 同Index,sep变为c字节
func IndexFunc(s []byte, f func(r rune) bool) int
// 返回符合f方法的字符首次出现的位置,找不到则返回-1
func IndexRune(s []byte, r rune) int
// 同Index,sep变为r字符
func Join(s [][]byte, sep []byte) []byte
// 以sep为连接符将子串列表连接成一个字节串
1 | s := [][]byte{{65,66},{67,68}} |
func LastIndex(s, sep []byte) int
// 查找s中最后一次出现sep的位置,找不到返回-1
1 | s := []byte("abcddabcd") |
func LastIndexAny(s []byte, chars string) int
// 查找s中最后一次出现chars中任意字符的位置,找不到返回-1
func LastIndexByte(s []byte, c byte) int
// 查找s中最后一次出现c字节的位置,找不到返回-1
func LastIndexFunc(s []byte, f func(r rune) bool) int
// 查找s中符合f方法的字符位置,找不到返回-1
func Map(mapping func(r rune) rune, s []byte) []byte
// 将s中的r替换成mapping(r)返回的字符,如果mapping返回负值,则丢弃
1 | rot13 := func(r rune) rune { |
func Repeat(b []byte, count int) []byte
// 返回子串b重复count次后的串
1 | fmt.Printf("%s\n", bytes.Repeat([]byte("Abc"), 3)) // AbcAbcAbc |
func Replace(s, old, new []byte, n int) []byte
// 将s中的前n个old替换成new,如果n<0则替换全部
1 | s := []byte("Bob takes you to Bob's house.") |
func Runes(s []byte) []rune
// 将s转换成[]rune型
func Split(s, sep []byte) [][]byte
// 以sep作为分隔符将s拆分成多个子串。
// 如果sep为空,则将s拆分成Unicode字符列表
func SplitN(s, sep []byte, n int) [][]byte
// 同Split,但可指定拆分次数n,超出n的部分不进行拆分
func SplitAfter(s, sep []byte) [][]byte
// 同Split,但是每个子串都包含分隔符sep
func SplitAfterN(s, sep []byte, n int) [][]byte
// 同SplitAfter,但可指定拆分次数n。
func Title(s []byte) []byte
// 将s中所有单词的首字符修改为Title格式返回
// Bug: 不能很好的处理Unicode标点符号分隔的单词。
func ToLower(s []byte) []byte
// 将s中的字符全部替换成小写并返回
func ToUpper(s []byte) []byte
// 将s中的字符全部替换成大小并返回
func ToTitle(s []byte) []byte
// 将s中的字符全部替换成标题并返回
func ToLowerSpecial(c unicode.SpecialCase, s []byte) []byte
// 使用指定的映射表将 s 中的所有字符修改为小写格式返回。
func ToUpperSpecial(c unicode.SpecialCase, s []byte) []byte
// 使用指定的映射表将 s 中的所有字符修改为大写格式返回。
func ToTitleSpecial(c unicode.SpecialCase, s []byte) []byte
// 使用指定的映射表将 s 中的所有字符修改为标题格式返回。
func Trim(s []byte, cutset string) []bytefunc TrimLeft(s []byte, cutset string) []bytefunc TrimRight(s []byte, cutset string) []byte
// 以上方法返回去掉s两边(左边、右边)包含在cutset中字符的切片
func TrimFunc(s []byte, f func(r rune) bool) []bytefunc TrimLeftFunc(s []byte, f func(r rune) bool) []bytefunc TrimRightFunc(s []byte, f func(r rune) bool) []byte
// 以上方法返回去掉s两边(左边、右边)符合f方法字符的切片
func TrimPrefix(s, prefix []byte) []byte
// 去掉s的前缀prefix
func TrimSuffix(s, suffix []byte) []byte
// 去掉s的后缀suffix
func TrimSpace(s []byte) []byte
// 去掉两边的空白
func NewBuffer(buf []byte) *Buffer
// 将buf包装成bytes.Buffer对象
func NewBufferString(s string) *Buffer
// 将s转换成[]byte后,包装成bytes.Buffer对象
func NewReader(b []byte) *Reader
// 将b包装成bytes.Reader对象
Buffer结构体
1 | // A Buffer is a variable-sized buffer of bytes with Read and Write methods. |
Buffer的方法:
func (b *Buffer) Bytes() []byte
// 引用未读取部分的数据切片(不移动读取位置)
func (b *Buffer) Cap() int
// 返回缓冲区容量
func (b *Buffer) Grow(n int)
// 自动增加缓存容量,以保证有n字节的剩余空间
// 如果n<0或者无法增加容量则会报Panic
func (b *Buffer) Len() int
// 返回未读缓冲区的字节长度,b.Len()==len(b.Bytes())
func (b *Buffer) Next(n int) []byte
// 返回缓冲区中的下n个字节数据的切片,并推进读取位置(类似于返回的字节数据已经被读取)。
// 如果n大于缓冲区长度,则返回整个缓冲区数据。
// 返回的切片仅在下一次调用Read或Write方法前有效。
func (b *Buffer) Read(p []byte) (n int, err error)
// 从缓冲区读取len(p)个字节或整个缓冲区到p中,返回读取的字节数n,如果没有数据可返回,则err=io.EOF。
func (b *Buffer) ReadByte() (byte, error)
// 从缓冲区读取一个字节并返回,如果没有可返回的数据,err=io.EOF。
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error)
// 从缓存中读取数据直到遇到delim时停止并返回包含delim的切片。
// 如果期间遇到错误,则返回遇到错误之前读取的数据并返回err。
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error)
// 从r中读取数据直到遇到EOF并且写入缓存区,必要时会增大缓存。
// 返回读取到的字节数量n,遇到除了EOF的其他错误也会返回结果。
// 如果缓存变的太大将会报一个ErrTooLarge的Panic错误。
func (b *Buffer) ReadRune() (r rune, size int, err error)
// 从缓存中读取并返回下一个UTF8编码字符,没有合适的字节则返回io.EOF。
func (b *Buffer) ReadString(delim byte) (line string, err error)
// 从缓存中读取直到第一次遇到delim字节,并作为string返回这个包含delim的数据。
func (b *Buffer) Reset()
// 将b重置并清空数据,如同Truncate(0)。
func (b *Buffer) String() string
// 将缓冲区所有未读数据作为string返回,如果b是nil,则返回”
func (b *Buffer) Truncate(n int)
// 从缓冲区中丢弃第n个未读数据之后数据,如果n<0或n>Cap则报Panic。
func (b *Buffer) UnreadByte() error
// 撤销最近一次的读操作中的最后字节数据。
// 如果在这之前执行了write或者最后一次读取返回了错误或者最后读取了空字节,则该方法会返回一个错误。
func (b *Buffer) UnreadRune() error
// 类似UnreadByte(),但是严格要求最后一次读取是Rune,否则报错。
func (b *Buffer) Write(p []byte) (n int, err error)
// 将p中的数据写入缓存,并返回写入的字节数n和可能发生的错误。
func (b *Buffer) WriteByte(c byte) error
// 往缓存中写入一个字节c并返回可能发生的错误(通常是nil)。
// 如果缓存扩容太大,则会报一个ErrTooLarge的Panic。
func (b *Buffer) WriteRune(r rune) (n int, err error)
// 同WriteByte,返回写入长度和可能发生的错误(通常是nil)。
func (b *Buffer) WriteString(s string) (n int, err error)
// 同WriteByte,将s的内容写入缓存,返回写入长度和可能发生的错误。
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error)
// 将缓存数据写入w直到写入完毕或发生错误。
Buffer的示列:
1 | package bytes |
Reader结构体
1 | // bytes.Reader 实现了如下接口: |
Reader的方法:
func (r *Reader) Len() int
// 返回未读部分的数据长度。
func (r *Reader) Size() int64
// 返回底层数据的总长度。
func (r *Reader) Reset(b []byte)
// 将底层数据切换为b,同时复位所有标记。
func (r *Reader) Read(b []byte) (n int, err error)func (r *Reader) ReadAt(b []byte, off int64) (n int, err error)func (r *Reader) ReadByte() (byte, error)func (r *Reader) ReadRune() (ch rune, size int, err error)func (r *Reader) Seek(offset int64, whence int) (int64, error)func (r *Reader) UnreadByte() errorfunc (r *Reader) UnreadRune() errorfunc (r *Reader) WriteTo(w io.Writer) (n int64, err error)
Reader的示列:
1 | package bytes |
一天一个Golang包,慢慢学习之“bufio”
今天学习带缓存的I/O操作,基础包“bufio”中有bufio.go和scan.go两个文件
官方pkg地址:https://golang.org/pkg/bufio/
包方法
func NewReadWriter(r *Reader, w *Writer) *ReadWriter
// 将r和w封装为一个bufio.Readwriter对象
func NewReader(rd io.Reader) *Reader
// 将rd封装为一个bufio.Reader对象(缓存大小默认4096)
func NewReaderSize(rd io.Reader, size int) *Reader
// 将rd封装成一个拥有size大小缓存的bufio.Reader对象
func NewScanner(r io.Reader) *Scanner
// 创建一个Scanner来扫描r
func NewWriter(w io.Writer) *Writer
// 将w封装成一个bufio.Writer对象(缓存大小默认4096)
func NewWriterSize(w io.Writer, size int) *Writer
//将w封装成一个拥有size大小缓存的bufio.Writer对象
Reader结构体
1 | // Reader 实现了对io.Reader对象的缓冲功能 |
func (b *Reader) Buffered() int
// 返回缓存中的数据长度
func (b *Reader) Discard(n int) (discarded int, err error)
// 丢弃接下来的n个字节,返回丢弃的字节长度
func (b *Reader) Peek(n int) ([]byte, error)
// 返回前n字节的缓存切片
func (b *Reader) Read(p []byte) (n int, err error)
// 读取len(p)个字节到p中。
// 如果len(p)>缓存大小,且缓存不为空,则读取全部缓存。
// 若缓存为空,则从底层io.Reader直接读取
func (b *Reader) ReadByte() (byte, error)
// 读出一个字节并返回
func (b *Reader) ReadBytes(delim byte) ([]byte, error)
// 查找delim并读取delim及其之前的所有数据(byte切片)
// 如果在找到delim之前发生错误,则返回发生错误之前的数据和error。
// 当找不到delim的时候,err!=nil
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error)
// 返回一个单行数据(切片),不包括行尾标记。
// 如果在缓存中找不到行尾标记,isPrefix为true,表示查找未完成,否则isPrefix为false
func (b *Reader) ReadRune() (r rune, size int, err error)
// 读取一个UTF8字符和字符的编码长度。
// 如果UTF8序列无法解码出一个正确的Unicode字符,则只读出一个字节,并返回U+FFFD字符,size返回1。
func (b *Reader) ReadSlice(delim byte) (line []byte, err error)
// 查找delim并读取delim及其之前的所有数据(byte切片-引用)
func (b *Reader) ReadString(delim byte) (string, error)
// 查找delim并读取delim及其之前的所有数据(字符串)
func (b *Reader) Reset(r io.Reader)
// 丢弃任何缓存数据,重置所有状态并切换io.Reader到r
func (r *Reader) Size() int
// 返回(底层)缓存的字节长度
func (b *Reader) UnreadByte() error
// 撤销最后一次读出的一个字节
func (b *Reader) UnreadRune() error
// 撤销最后一次读出的Unicode字符
// 如果最后一次执行的不是ReadRune(),则返回一个错误
func (b *Reader) WriteTo(w io.Writer) (n int64, err error)
// 实现了io.WriteTo接口。
// 可以(可能)对底层Reader的Read方法进行多次调用。
// 如果底层Reader支持WriteTo方法,则直接调用底层方法,无需缓存。
Reader的示例:
1 | package bufio |
Writer结构体
1 | // Writer 实现了对io.Writer对象的缓冲功能 |
func NewWriter(w io.Writer) *Writer
// 将w封装成一个bufio.Writer对象,缓存大小为4096.
func NewWriterSize(w io.Writer, size int) *Writer
// 将w封装成一个拥有size大小缓存的bufio.Writer对象
func (b *Writer) Available() int
// 返回缓存中的可用空间
func (b *Writer) Buffered() int
// 返回缓存中未提交的数据长度
func (b *Writer) Flush() error
// 将缓存中的数据提交到底层io.Writer中
func (b *Writer) ReadFrom(r io.Reader) (n int64, err error)
// 实现了io.ReaderFrom接口。
// 如果底层writer支持ReadFrom方法且b的缓存数据为空,则直接调用底层的ReadFrom方法,不使用缓存。
func (b *Writer) Reset(w io.Writer)
// 丢弃所有未被提交的缓存数据,重置所有状态并切换io.Writer到w
func (b *Writer) Size() int
// 以字节为单位返回(底层)缓冲区大小
func (b *Writer) Write(p []byte) (nn int, err error)
// 将p中的数据写入b中,返回写入的字节数
// 如果写入的字节数小于p的长度,则返回错误
func (b *Writer) WriteByte(c byte) error
// 写入一个字节
func (b *Writer) WriteRune(r rune) (size int, err error)
// 写入一个UTF8编码字符
func (b *Writer) WriteString(s string) (int, error)
// 写入一个字符串,返回写入的字节数
Writer的示列:
1 | package bufio |
Scanner结构体
1 | // Scanner为读取数据提供了便捷的接口,这些数据包括但不限于有换行分界符的文本文件。 |
func (s *Scanner) Buffer(buf []byte, max int)
// 用于设置自定义缓存以及可扩展范围,如果max小于len(buf),则buf的尺寸将固定不可调。
// Buffer必须在第一次Scan之前设置,否则引发Panic。
// 默认情况下,Scanner将会使用一个4096-bufio.MaxScanTokenSize大小的内部缓存。
func (s *Scanner) Bytes() []byte
// 将最后一次扫描出的‘指定部分’作为切片(引用)返回
// 下一次的扫描会覆盖本结果
func (s *Scanner) Err() error
// 返回扫描过程中遇到的非EOF错误
func (s *Scanner) Scan() bool
// 扫描数据中的‘指定部分’
func (s *Scanner) Split(split SplitFunc)
// 设置Scanner的分切函数,必须在Scan方法之前调用
func (s *Scanner) Text() string
// 最后一次扫描出的‘指定部分’作为String返回
Scanner的示例:
1 | package bufio |
另外的参考: